Exploring the Use of YOLO V7 for Object Detection in Robotics
Table of Contents
Overview #
Object detection is a fundamental task in robotics, and the ability to detect and track objects in real-time is crucial for various applications, such as autonomous driving, object sorting, and surveillance. You Only Look Once (YOLO) is a popular algorithm for object detection, and its latest version, YOLOv7, has set a new state-of-the-art in real-time object detection.
In this blog post, we will explore the groundbreaking features of YOLOv7, which include its exceptional accuracy and speed. We will discuss how YOLOv7 outperforms other real-time object detectors, making it an ideal candidate for use in robotics applications.
Background #
Object detection is a process of identifying and locating objects within an image or video. The YOLO algorithm, introduced in 2015, revolutionized the field of object detection by enabling real-time object detection. YOLO divides the input image into a grid and predicts bounding boxes and class probabilities for each grid cell. Since its inception, YOLO has undergone several upgrades, with each new version improving on the previous one’s accuracy and speed.
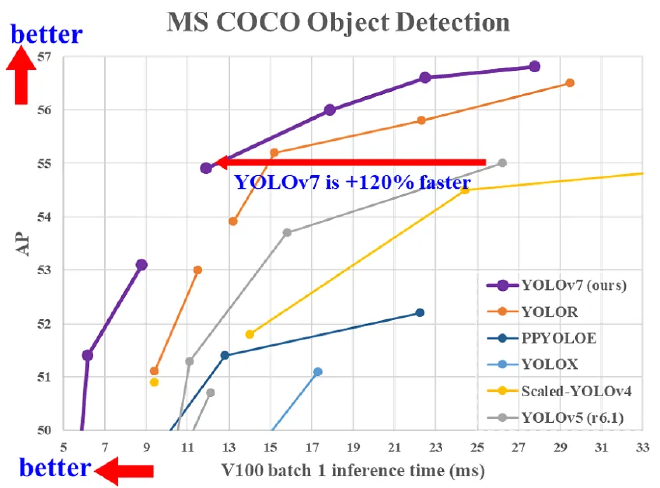
YOLOv7, the on of the latest version of YOLO, was introduced in 6 Jul 2022. It has set a new benchmark for real-time object detection by outperforming all known object detectors in terms of both speed and accuracy. YOLOv7 has the highest accuracy, 56.8% AP, among all known real-time object detectors with 30 FPS or higher on GPU V100.
To quote the paper
Abstract
YOLOv7 surpasses all known object detectors in both
speed and accuracy in the range from 5 FPS to 160 FPS
and has the highest accuracy 56.8% AP among all known
real-time object detectors with 30 FPS or higher on GPU
V100. YOLOv7-E6 object detector (56 FPS V100, 55.9%
AP) outperforms both transformer-based detector SWINL
Cascade-Mask R-CNN (9.2 FPS A100, 53.9% AP) by
509% in speed and 2% in accuracy, and convolutionalbased
detector ConvNeXt-XL Cascade-Mask R-CNN (8.6
FPS A100, 55.2% AP) by 551% in speed and 0.7% AP
in accuracy, as well as YOLOv7 outperforms: YOLOR,
YOLOX, Scaled-YOLOv4, YOLOv5, DETR, Deformable
DETR, DINO-5scale-R50, ViT-Adapter-B and many other
object detectors in speed and accuracy. Moreover, we train
YOLOv7 only on MS COCO dataset from scratch without
using any other datasets or pre-trained weights. Source
code is released in https:// github.com/WongKinYiu/yolov7.
Evaluating the Performance of YOLOv7 Object Detection #
In comparison to YOLOv4, YOLOv5, and YOLOR, the YOLOv7 model was evaluated and trained using the same configurations. With its superior speed-to-accuracy ratio, the YOLOv7 outperforms all other state-of-the-art object detectors. Its ability to achieve 5 FPS to 160 FPS is unmatched by its predecessors, making it the fastest and most accurate model to date. Moreover, the YOLOv7 algorithm surpasses all other real-time object detection models, achieving the highest accuracy with a GPU V100 at 30 FPS or higher.
Use Case #
Robotics is a field that has witnessed tremendous growth in recent years. With the advent of advanced technologies, robots are becoming more intelligent, versatile, and capable of performing complex tasks. One area where robotics has made significant strides is in object detection. Object detection is a crucial component of many robotic applications, including autonomous driving, warehouse automation, and robotics-assisted surgeries.
The first step in using YOLOv7 is to train the model. Training a deep learning model requires a large dataset of images, along with corresponding labels. The YOLOv7 model requires an annotated dataset with bounding boxes around the objects of interest. Once the dataset is prepared, the next step is to train the YOLOv7 model using the dataset. The training process can take several hours or even days, depending on the size of the dataset and the computing resources available.
After training the model, it can be integrated into the robotic system. The YOLOv7 model can be deployed on various hardware platforms, including CPUs, GPUs, and FPGAs. For robotics applications, GPUs are the most commonly used hardware platform due to their high processing power and ability to handle complex tasks.
Once the YOLOv7 model is deployed on the hardware platform, it can be used for object detection. In a robotics project, object detection is typically performed in real-time, and the YOLOv7 model can process images or video streams in real-time. The output of the YOLOv7 model is a list of bounding boxes around the objects of interest, along with the confidence score of each detection. This output can be used by the robot to perform various tasks, such as object manipulation or navigation.
To read about my implementation of YOLO in a project
Conclusion #
The use of YOLOv7 for object detection in robotics has several advantages. Its high accuracy and real-time performance can enable robots to detect and track objects effectively. YOLOv7 has outperformed other state-of-the-art object detectors in terms of both speed and accuracy, making it an ideal candidate for use in various robotics applications. As YOLOv7’s source code is publicly available, it is accessible to developers and researchers worldwide, facilitating its use and further development.